CUDA 软件栈
CUDA 软件栈
深度学习等项目通常需要 GPU 的支持,而 CUDA 负责连接程序与硬件 GPU。CUDA 是由 NVIDIA 推出的一种通用并行计算架构,既是一种并行计算平台,也是一种编程模型。该架构使 GPU 能够解决复杂的计算问题。CUDA 的英文全称是 Compute Unified Device Architecture。
要正确配置 CUDA 环境,我们需要先了解程序是如何利用 GPU 运行的。CUDA 的软件栈(software stack)如下图所示: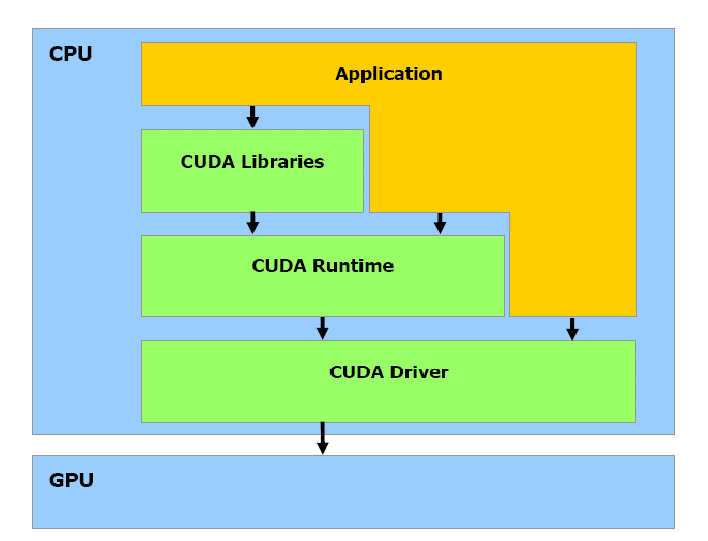
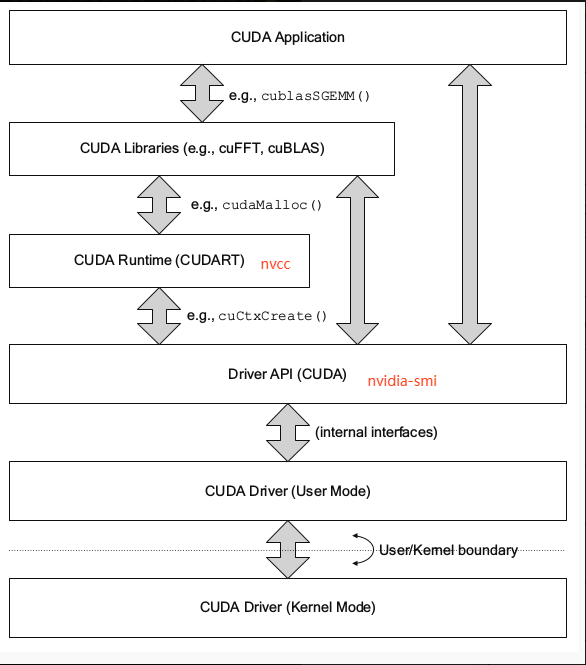
如上图,在编写 GPU 程序时,我们可以选择不同的方式与 GPU 交互:可以使用 CUDA Libraries 的高性能实现,调用 CUDA Runtime 提供的 API,或者直接调用底层的 CUDA Driver API。
CUDA Libraries:包括
CUDA提供的高性能函数库,用于简化开发者的工作。常见的库有:cuBLAS:基本线性代数子程序库,用于矩阵计算。cuDNN:深度学习库,为神经网络提供优化支持。- …
CUDA Runtime:
CUDA运行时 API,提供对 GPU 的高层次控制,可以通过定义 Kernel 函数实现并行计算,简化了与 GPU 的交互。CUDA Driver:
CUDA驱动 API,位于Runtime API的底层,直接与 GPU 硬件交互,适合高级用户进行定制化开发,例如动态加载模块等。
概念介绍
显卡
GPU 是显卡上的一块芯片,这也就是我们需要操纵的硬件部分。对于该部分需要了解的是,不同的N卡具有不同的计算能力(Compute Capability),这是直接与 GPU 挂钩的。不同型号 GPU 的计算能力见官网。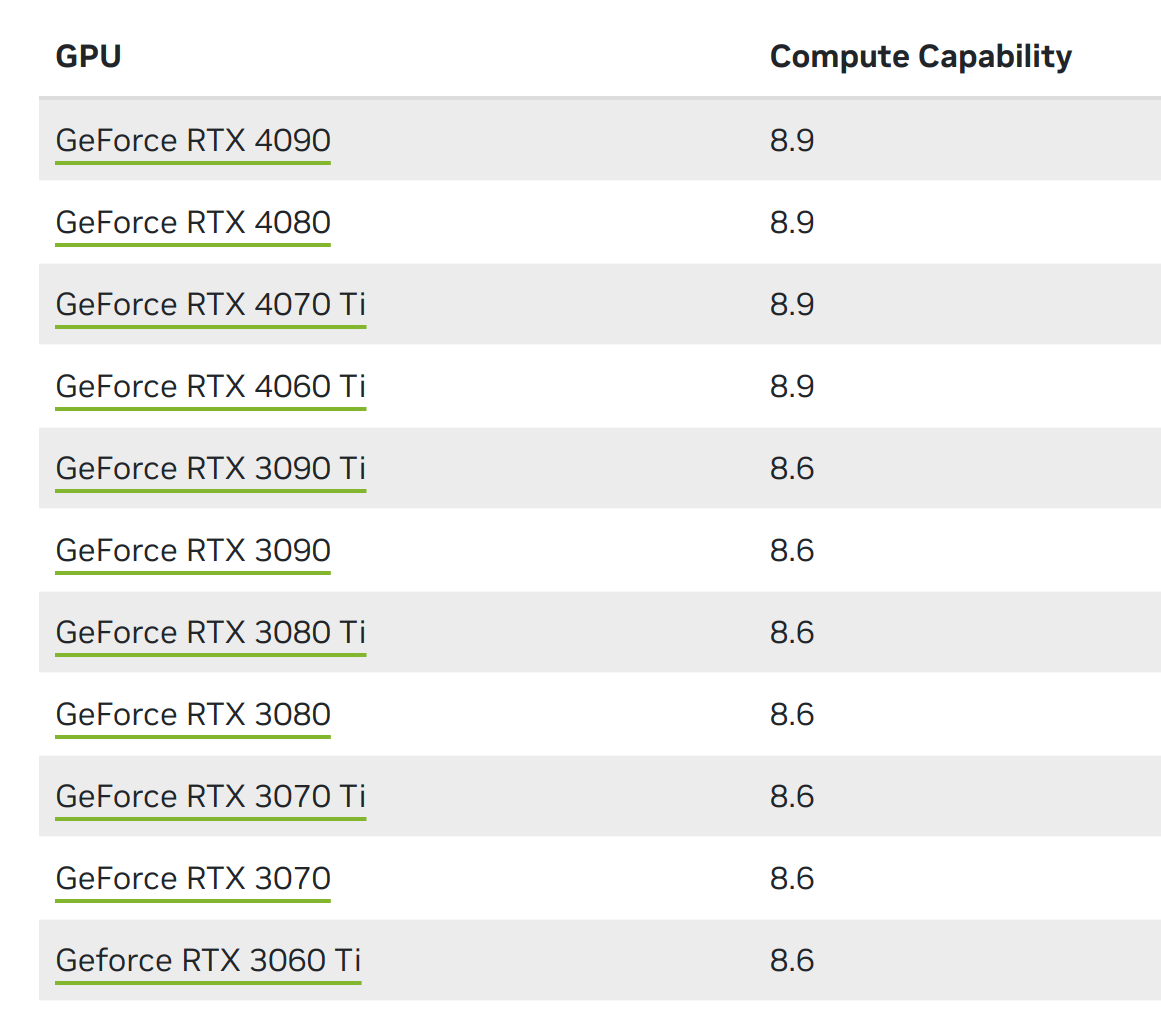
显卡驱动
显卡驱动是显卡与计算机连接的桥梁,可以让计算机识别到 GPU 硬件,因此必须正确安装。
NVIDIA Driver 是 NVIDIA 显卡的驱动软件。对于家用电脑,一般可以先在 官网 下载并安装显卡驱动。
下载后,可以通过命令查看驱动信息,如下图所示: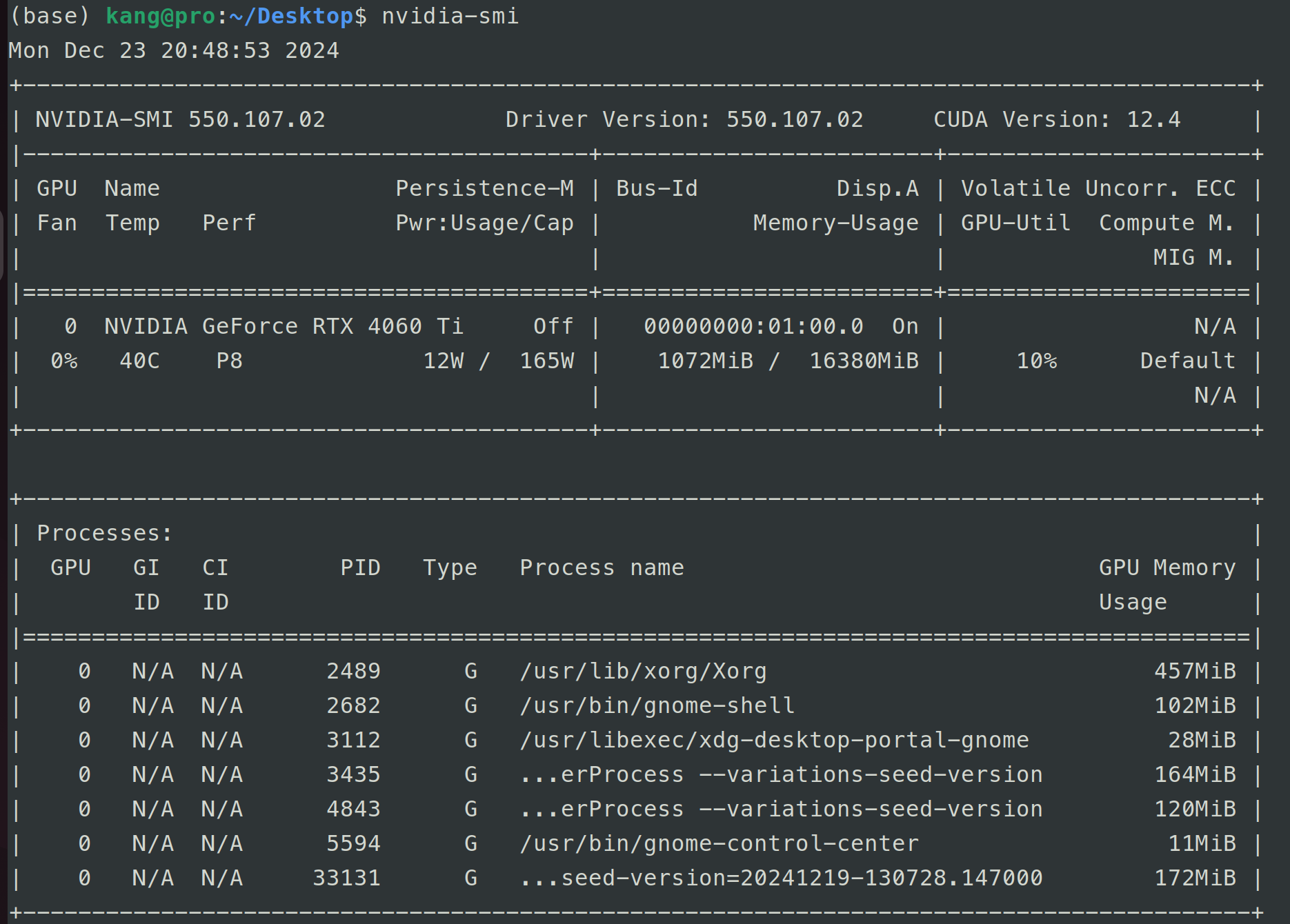
由图可知,当前驱动的版本为 550.107.02,同时发现 CUDA Version 为 12.4。这是因为 CUDA Driver 包含在驱动程序中,也就是说此时已经下载了上一部分提到的 CUDA Driver 层,版本为 12.4。
CUDA Toolkit
CUDA Toolkit 由以下组件组成:
Compiler:
CUDA-C和CUDA-C++编译器NVCC位于bin/目录中。它建立在NVVM优化器之上,而NVVM优化器本身构建在LLVM编译器基础结构之上。开发人员可以使用nvvm/目录下的 Compiler SDK 直接针对NVVM进行开发。Tools:提供一些工具,例如
profiler和debuggers,这些工具可以从bin/目录中获取。Libraries:以下列出的一些科学库和实用程序库可以在
lib/目录中使用(Windows 上的 DLL 位于bin/中),它们的接口位于include/目录中:cudart:CUDA Runtimecudadevrt:CUDA device runtimecupti:CUDA profiling tools interfacenvml:NVIDIA management librarynvrtc:CUDA runtime compilationcublas:BLAS (Basic Linear Algebra Subprograms,基础线性代数程序集)cublas_device:BLAS kernel interface- …
CUDA Samples:演示如何使用各种
CUDA和库 API 的代码示例。可在 Linux 和 Mac 的samples/目录中获得,Windows 上的路径是C:\ProgramData\NVIDIA Corporation\CUDA Samples。CUDA Driver:运行
CUDA应用程序需要系统至少有一个具有CUDA功能的 GPU 和与CUDA Toolkit兼容的驱动程序。
每个版本的CUDA Toolkit都对应一个最低版本的CUDA Driver。如果安装的CUDA Driver版本低于官方推荐版本,很可能无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序可以在后续发布的 Driver 上继续工作。通常,为了方便,在安装CUDA Toolkit时会默认安装CUDA Driver。
由以上可知,CUDA Toolkit 为我们编写 CUDA 程序提供了运行时,而无需直接使用底层的驱动程序。CUDA Toolkit 包含了编译器 nvcc,可以通过 nvcc -V 查看;同时也提供了一些链接库。由于这一层是由 Driver 层包装得来的,所以 CUDA Toolkit 会一同包含前文提到的 Driver。如果已经下载好驱动,则在下载 CUDA Toolkit 时无需勾选 Driver。
需要注意的是,CUDA Runtime 的版本对底层 Driver 有版本要求(底层支持上层)。
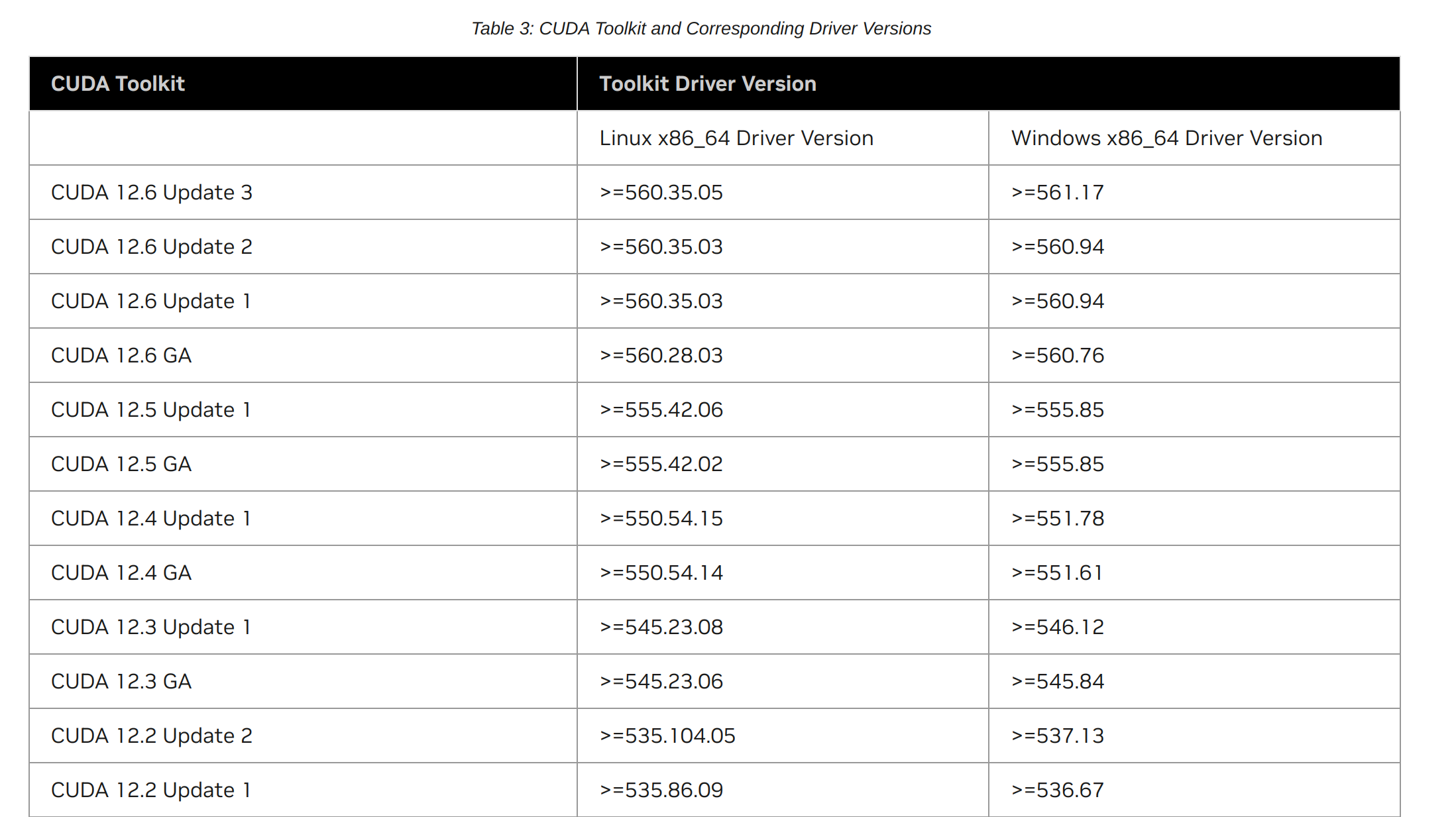
- 一方面,如下图所示,可以在 官网 中查看
CUDA Toolkit版本所要求的最低Driver版本。 - 另一方面,可以通过
nvidia-smi查看当前的CUDA Driver版本,并确保满足CUDA Driver >= CUDA Runtime的要求。
另一方面,CUDA 版本并不是只要足够小就能高枕无忧。一些新的架构(由计算能力体现)也需要较新版本的 CUDA。
对于 CUDA Toolkit 的版本选择,除了不能高于底层驱动的最大支持(CUDA Driver 版本),还需要符合硬件计算能力对 CUDA Toolkit 的要求(高于最低版本要求)。GPU 的算力与 CUDA 版本的对应关系可以通过 wiki 或 官网 获取。
cuDNN
cuDNN:cuDNN 的全称为 NVIDIA CUDA® Deep Neural Network library,是 NVIDIA 专门针对深度神经网络中的基础操作设计的基于 GPU 的加速库。cuDNN 为深度神经网络中的标准流程提供了高度优化的实现方式,例如 convolution、pooling、normalization 以及 activation layers 的前向和后向过程。
Pytorch
安装 CUDA 版 pytorch 时,会安装一个不完整的 CUDA Toolkit,pytorch 中可以调用 GPU 也是因为这个原因。
这个不完整的包主要包含在使用 CUDA 相关功能时所依赖的动态链接库,但不会安装底层的驱动程序和编译工具等。
因此,如果只使用 pytorch 编写深度学习应用,可以不用单独安装 CUDA Toolkit,而是在安装完底层驱动后,直接在 conda 创建的环境中安装 pytorch 以及相应的 CUDA 包即可。此时对于 CUDA 版本的选择与安装 CUDA Toolkit 时一致:
- 一方面,版本需要低于
CUDA Driver版本。 - 另一方面,版本需要支持 GPU 的计算能力。
而如果使用 C++ 编写 CUDA 程序(.cu 文件),则需要安装 NVIDIA Driver 和完整的 CUDA Toolkit,并使用 nvcc 进行编译。
参考: